雜湊表 Hash Map
雜湊表是以雜湊函數實作的關聯容器。透過雜湊函數,計算鍵(key)對應到容器內部的索引位置,進而找到對應的值(value)。一般來說,雜湊表最常見的實作是以一個簡單陣列儲存資料。
雜湊表的優勢是:
- 在資料量大時,仍然維持常數時間的高效能。
- 若資料數量上限已知,就可避免重新配置記憶體,效能更佳。
- 若資料形態已知,就可針對該資料形態找尋適合的雜湊函數最佳化。
而雜湊表相對有以下短處:
- 資料量不夠大時,單一操作需要雜湊計算,開銷相對高。
- 效能與雜湊函數息息相關,較差的函數容易雜湊碰撞,較佳函數計算成本通常較高。
- 只能以某種偽隨機的順序疊代雜湊表。
本次實作的程式碼置於
rust_algorithm_club::collections::HashMapAPI 文件中。
概念
建立雜湊表的第一步,就是配置一定大小的陣列(通常稱為 bucket array),來儲存對應索引的鍵值對。我們以建立電話簿為例,儲存人名與號碼的對應關係。
Create an empty phone book with some blank slots.
+--------------+
| 0: |
+--------------+
| 1: |
+--------------+
| 2: |
+--------------+
| 3: |
+--------------+
我們嘗試插入第一筆資料,記錄 Frodo 以及他的手機號碼 88-7-666。
- 透過雜湊函數,計算出 Frodo 的索引值為 1。
- 將 88-7-666 插入 table[1] 的位置上。
table[1] 這種 bucket array 下的個別索引空間,通常稱為一個 slot 或 bucket。
Fordo: hash_function(Frodo) --> 1
+-------------+
| 0: |
+-------------+
Frodo --> | 1: 88-7-666 |
+-------------+
| 2: |
+-------------+
| 3: |
+-------------+
嘗試插入另外二筆資料,記錄 Sam 的手機 11-2-333,以及 Gollum 的手機 00-0-000。
- 透過雜湊函數,計算出 Sam 的索引值為 2。
- 將 11-2-333 插入 table[2] 的位置上。
- 透過雜湊函數,計算出 Gollumn 的索引值為 0。
- 將 00-0-000 插入 table[0] 的位置上。
Sam: hash_function(Sam) --> 2
+-------------+
| 0: |
+-------------+
| 1: 88-7-666 |
+-------------+
Sam --> | 2: 11-2-333 |
+-------------+
| 3: |
+-------------+
Gollum: hash_function(Gollum) --> 0
+-------------+
Gollum -> | 0: 00-0-000 |
+-------------+
| 1: 88-7-666 |
+-------------+
| 2: 11-2-333 |
+-------------+
| 3: |
+-------------+
若需要取得 Sam 的手機號碼,只要
- 透過雜湊函數,計算出 Sam 的索引值為 2。
- 從 table[2] 的索引位置上,找到 Sam 的手機號碼
Sam: hash_function(Sam) --> 2
+-------------+
| 0: 00-0-000 |
+-------------+
| 1: 88-7-666 |
+-------------+
Sam --> | 2: 11-2-333 | --> Sam's phone number
+-------------+
| 3: |
+-------------+
這就是最基本,以陣列實作的雜湊表了。
然而,你可能已經開始好奇了。
- 雜湊是什麼?怎麼知道要映射到哪個索引位置?
- 雜湊函數是否會計算出相同的索引值?要如何解決?
- 若預先配置的陣列填滿了,該如何處理?
接下來,將探討這幾個魔術般的因子,從簡單介紹雜湊函數,到如何解決雜湊碰撞,最後探討陣列塞滿重配置解決方案。
註:雜湊表也可以搜尋樹等其他資料結構實作,在此不深入討論。
雜湊
所謂的雜湊函數,就是一種將「較寬的定義域映射到較窄值域」的函數。簡單來說,就是輸入任意值到此函數,則輸出值會落在一已知範圍。再白話一點,雜湊函數就是用來「化繁為簡」,把複雜多變的東西,透過函數生成簡化版本。此外,相同的輸入鍵,必須得到相同的輸出雜湊值,這是雜湊函數很重要的一個特性,以虛擬碼表示:
key1 == key2 -> hash(key1) == hash(key2)
「映射」這部分只是使用雜湊的一小步。雜湊表根據程式實作的不同,底層儲存資料的形式也不盡相同,為了完全放入陣列中,通常會對雜湊值(雜湊函數的計算結果)取模(modulo)。也就是說:假設有長度為 n 的陣列。1)先對 key 取雜湊值。2)再對雜湊值取模,確認索引值落在陣列內部。
Assumed: array_size = n
hash_value = hash_function(key) // 1
index = hash_value % array_size // 2
如此一來,所有可能的值都會落在陣列內,這就是最簡單普遍的雜湊兩步驟:計算雜湊值﹢取模。
選擇雜湊函數
接下來,你會緊接著向問第二個問題「函數計算出相同索引值該怎麼辦?」不同輸入產生相同雜湊值,多個值映射到同個索引上,這種狀況科學家稱之雜湊碰撞(hash collision)。
首先,要瞭解雜湊函數本身就是時空間的權衡,如果記憶體空間夠多,那讓輸入值與雜湊值呈一對一的完美關係,就不會出現碰撞;大多數情況,尤其是實作泛用的雜湊函式庫,無法預期輸入資料的範圍,實務上會鎖定一個輸出雜湊值的範圍,僧多粥少,難免碰撞。
好的雜湊函數還必須符合一些條件:
- 同一筆輸入資料,必須得到相同的雜湊值。
- 結果必須能夠高效的計算出來(預期為常數時間)。
- 任意輸入資料所得之雜湊值在值域內需接近均勻分佈(uniform distribution),才能減少碰撞機率。
但總歸一句,欲達成上述條件,就是一種權衡取捨,例如,加密雜湊函數(cryptographic hash function)即是非常優秀的雜湊函數,但相對需付出更高的計算成本。
更多雜湊函數相關的討論,會另撰專文。
處理雜湊碰撞
既然雜湊函數人生在世難免碰撞,科學家也研究幾個處理雜湊碰撞的策略,分別是 separate chaining 與 open addressing。
Separate chaining 可以說是最直觀的做法,就是設法讓同一個索引下,可以儲存多個碰撞的值。依據儲存資料的形式,可分為幾種實作:
- 鏈結串列:以鏈結串列(linked list)儲存元素。發生碰撞時,新的元素串接在既有元素之後。
- 動態陣列:新增元素時,在該位址配置動態陣列(dynamic array)儲存元素。發生碰撞時,直接將新元素加在陣列尾端。
不同實作方式有各自優缺點,例如串列版本容易實作,但需額外儲存指標資訊;用動態陣列,則會有更好的 CPU caching,但相對地碰撞過多則需要重配置陣列。
以 ASCII 表述使用串列實作 separate chaining 示意圖如下:
... assumed hash values of Gimli and Gollum collided.
+----------------+
+-> |Gollum, 00-0-000| (linked list)
| +----------------+
| |
Gimli -+ | v
| | +---------------+
| +--------+ | |Gimli, 99-9-999|
Gollum -->|0: ptr |--+ +---------------+
+--------+
Frodo -->|1: ptr |----> +---------------+
+--------+ |Frodo, 88-7-666|
Sam -->|2: ptr |--+ +---------------+
+--------+ |
|3: null | +-> +---------------+
+--------+ | Sam, 11-2-333 |
(main bucket array) +---------------+
而這邊也有精美的實作示意圖,將串列首個元素 head 直接放置在 slot 中的作法,減少一次指標操作。
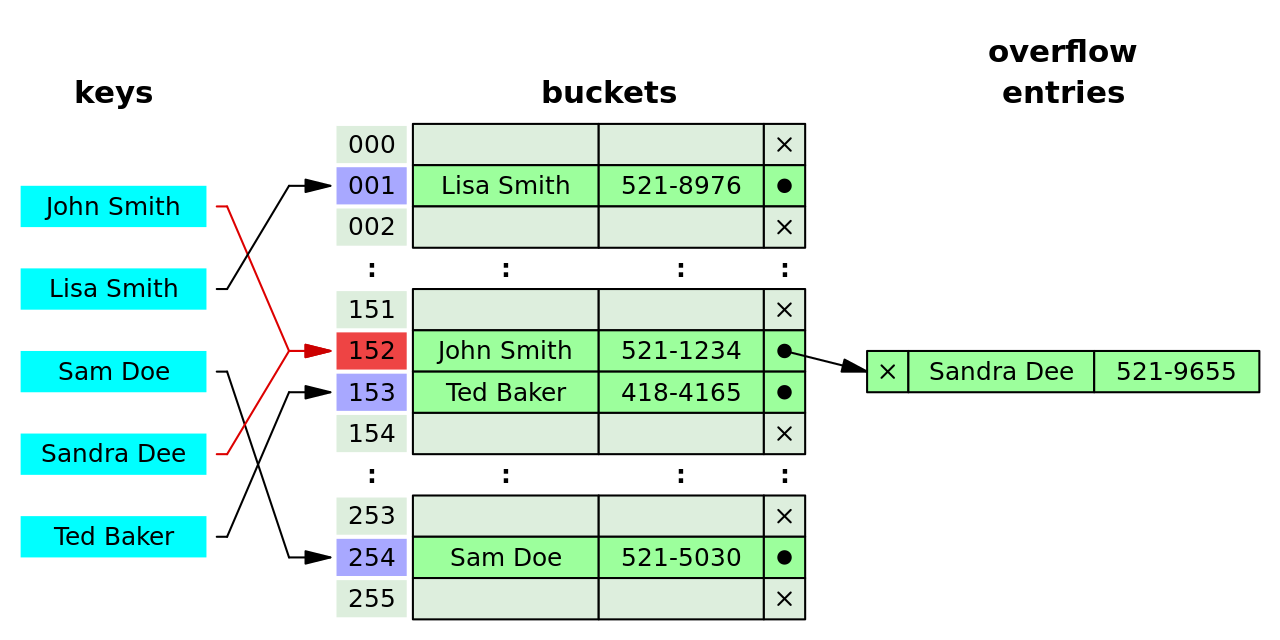
(利用 separate chaining 實作的雜湊表,並將串列第一個元素放在 bucket array 中)
另一方面 Open addressing 則走完全不同的套路,不額外配置儲存空間給碰撞的元素,而是繼續在同個陣列內「探測」其他可用的 slot,再把資料塞進尚未被佔據的 slot 中。而 Open addressing 依據不同探測序列(probe sequence)有不同實作,常見的有:
- Linear probing:從發生碰撞索引開始,依序往下一個 slot 探測是否可用,因此得名「線性」。
- Quadratic probing:從碰撞索引開始,間隔以二次式增加往下探測可用 slot,如 $i + 1^2, i + 2^2, i + 3^2$。
- Double hashing:以固定間隔大小 $k$(probe distance),依序探測 $i + k, i + k \cdot 2 ...$ 的 slot 是否為空。而這個間隔是以另外一個雜湊函數計算所得,因此得名「雙雜湊」。
$i$ 為發生碰撞的索引位置。
這些方法的差異主要在於 CPU caching 的效能,以及 HashMap 資料的群聚效應(clustering)的敏感程度。當然,論 caching 絕對非 linear probing 莫屬,但 linear probing 以線性一個挨一個探勘,效能較容易受雜湊值群聚影響。
以下是 linear probing(間隔 = 1)的示意圖。

動態調整雜湊表大小
若資料的筆數已知,那初始配置的陣列大小設定與資料筆數成比例,就不必擔心雜湊表空間不夠,需要重新配置(reallocate)儲存空間的困擾。倘若資料量未知,而最初配置的 bucket array 滿了,該如何重新配置呢?
動態調整大小對雜湊表來說,不同於一般動態陣列,舊的雜湊表若要對應到新雜湊表,是每個鍵都需要重新計算雜湊值(rehash),成本相對較高。因此,減少動態調整的次數,可說是調教雜湊表的重點之一。說到調教雜湊表,必定要瞭解一個重要指標:load factor。
$$\text{load factor} = \frac{n}{k}$$
$n$:已放入雜湊表內的資料總數。
$k$:雜湊表配置的儲存空間(bucket 總數)。
Load factor 代表目前雜湊表的「使用率」,若三筆資料放在四個 bucket 內,則 load factor 為 $3/4 = 75%$。Load factor 太大會更容易碰撞,會有效能上的影響;太小則代表過多冗餘空間沒有使用。如何維持 load factor 在一定範圍內至關重要。一般來說,75% 的 load factor 就可以準備重新配置雜湊表了,當然,這個門檻仍要以實作經驗為主,例如 Rust 的 HashMap 使用了 Robin Hood Hashing,將 load factor 調教到 90%。
重配置雜湊表與動態陣列的動態調整大小雷同,達到某個門檻值,就會將底層陣列大小翻倍。為了避免開銷過高,通常元素減少時,不會主動調整大小,而是提供一個 shrink_to_fit 一類的方法,讓呼叫端自行決定釋放多餘空間的時機。
架構設計
在介紹架構設計之前,我們先來瞭解 Rust 雜湊相關的觀念與 trait。
Hash and Eq
要實作雜湊函數,當然可以自幹計算雜湊值的函式來用,那為什麼還要使用 Rust 定義好的 Hash 呢?當然是希望將雜湊的介面抽象化,只要型別宣告符合 Hash trait,任何人都可以輕鬆計算雜湊值。而實作 Hash 很簡單,只要寫一個 fn hash(),呼叫端就能透過它計算雜湊,例如:
#![allow(unused)] fn main() { use std::hash::{Hash, Hasher}; struct Car { brand: String, } impl Hash for Car { fn hash<H: Hasher>(&self, state: &mut H) { self.brand.hash(state); } } }
光是計算雜湊值還不夠,要確定「當鍵相等時,其雜湊值也相等」這極為重要的雜湊特性,這時候除了實作 Hash trait,Eq trait 也要同時實作,該型別才能夠「被比較」,標準函式庫的 HashMap 的鍵就是實作 Hash + Eq 的型別,詳情請參閱 trait 的文件說明。
綜合以上,可以大膽定論,我們將實作的雜湊表的 key 一定符合 K: Hash + Eq,key 本身才能相互比較(實作 Eq),並開放呼叫端自定義型別實作不同的雜湊計算方式(實作 Hash)。
為了方便計算雜湊值,我們寫了一個輔助函式,以達成雜湊兩步驟:計算雜湊值﹢取模。其中,我們使用了 Rust 預設的雜湊演算法 DefaultHasher,省下實作雜湊函數的功夫。
#![allow(unused)] fn main() { fn make_hash<X>(x: &X, len: usize) -> Option<usize> where X: Hash + ?Sized, // 1 { if len == 0 { return None; } // 2 let mut hasher = DefaultHasher::new(); // 3 x.hash(&mut hasher); Some(hasher.finish() as usize % len) } }
X泛型參數除了Hash,還必須是 Dynamically Sized Type(DST,型別記作?Sized)- 防止以 0 取模(
%modulo),除數不能為 0。 - Rust 的 hasher 是一狀態機,每餵他吃資料,
hasher.finish()產生的雜湊值就不同,為了確保雜湊相同,這裡每次呼叫就建立一個全新的 hasher。
所謂 Dynamically Sized Types(DSTs) 是指無法靜態得知大小的型別,例如 slice,或是一個函式的參數接受實作某個 trait 型別(trait object),而在 Rust 幾乎所有基礎型別預設都是
Sized編譯期就可得知大小。而在這裡我們不關心知道實作該型別可否靜態決定大小,只需知道它是否實作Hash,所以明確添加?Sized表示接受 DSTs。
記憶體佈局
我們嘗試建立可以儲存 key-value pair 的結構體,裡面配置一個 bucket array buckets。其中 K 泛型參數是準備計算雜湊的鍵,而 V 則是與鍵配對的資料。
#![allow(unused)] fn main() { pub struct HashMap<K, V> where K: Hash + Eq { buckets: Vec<(K, V)>, } }
可是,用單一 Vec 儲存所有資料,萬一雜湊碰撞,不同鍵指向同個索引值該如何?這次先挑選相對容易的方案 separate chaining 處理碰撞,並以 Vec 動態陣列作為每個 bucket 儲存碰撞元素的容器,因此,buckets 陣列裡面改存 Bucket 陣列,而 Bucket 則儲存真正的 key-value pair。
#![allow(unused)] fn main() { type Bucket<K, V> = Vec<(K, V)>; // 1 pub struct HashMap<K, V> where K: Hash + Eq { buckets: Vec<Bucket<K, V>>, // 2 len: usize, // 3 } }
- 宣告 bucket 的型別
Bucket,實際上是一個 type alias 指向儲存鍵值(K, V)的動態陣列。 - 將
HashMap.buckets改為儲存Bucket的動態陣列。 - 新增
len記錄容器當前鍵值對數目,在增刪資料時,len都會同步更新。
之所以使用額外的成員記錄資料數目,是為了計算數目能在 O(1) 時間內完成,nested array 動態疊代每個 Bucket 計算的成本太高。
這就是 Vector-based separate chaining HashMap 的記憶體佈局,來看張精美的雜湊表架構佈局圖吧!

基本操作
雜湊表有以下幾個基本操作:
new:初始化一個空雜湊表。with_capacity:配置特定數量 bucket 的雜湊表。get:取得指定鍵對應的資料。get_mut:取得指定鍵對應的資料,並可寫入修改(mutable)。insert:在任意位置插入一組鍵值對。remove:移除任意位置下的鍵值對。clear:清除所有鍵值對。is_empty:檢查雜湊表是否沒有任何鍵值對。len:檢查目前鍵值對的數目。bucket_count:檢查目前 bucket 的數目。
以及幾個內部方法:
try_resize:根據給定條件,決定調整 bucket 數目的時機,讓 load factor 維持最適狀態。make_hash:從輸入資料產生雜湊值,再模除 bucket 數,得到輸入資料對應的索引位置。
接下來解釋實作的重點。
初始化與預設值
雜湊表初始化相對容易,一樣慣例使用 new。
#![allow(unused)] fn main() { impl<K, V> HashMap<K, V> where K: Hash + Eq { pub fn new() -> Self { Default::default() } /// ... } impl<K, V> Default for HashMap<K, V> where K: Hash + Eq { fn default() -> Self { Self { buckets: Vec::<Bucket<K, V>>::new(), len: 0 } } } }
這裡為了符合人因工程,使用了 Default trait 設定初始值。此外,由於 Rust 的容器型別慣例上沒有任何元素時,不會配置任何記憶體空間,僅有初始的 pointer。 HashMap 初始化後,記憶體空間僅需
buckets的Vec佔據 3 個 usize 大小(一個 heap 指標,兩個記錄容量與長度的 usize。len本身佔據 1 個 usize 大小。
所以預設初始化的 HashMap 在 64bit machine 上佔 4 * usize = 32 bytes。
為了後續實作 resize 容易些,同時實作了指定 bucket 數目的建構式。
#![allow(unused)] fn main() { pub fn with_capacity(cap: usize) -> Self { let mut buckets: Vec<Bucket<K, V>> = Vec::new(); for _ in 0..cap { buckets.push(Bucket::new()); } Self { buckets, len: 0 } } }
很清楚地,同樣建立一個空的 bucket array,再預先配置給定數量的 Bucket 。len 則因為沒有開始增加新值,而設定為 0。
存取單一元素
存取元素的實作也非常直觀,
- 使用
make_hash計算出 key 對應的索引位置, - 再透過
Vec::get取得該索引下的 bucket,找不到時則返回None, - 找到 bucket 後則對整個 bucket 線性搜索與 key 相同的鍵值對。
#![allow(unused)] fn main() { pub fn get(&self, key: &K) -> Option<&V> { let index = self.make_hash(key)?; self.buckets.get(index).and_then(|bucket| bucket.iter() .find(|(k, _)| *k == *key) .map(|(_, v)| v) ) } }
事實上,這個 get 不是非常方便使用,當我們透過 HashMep::get 搜尋特定鍵時,必須傳入一模一樣的型別,例如 HashMap<&str, u8> 就只能透過相同的 borrowed value &str 搜索,而不能透過 owned value &String 尋找,就算兩個型別可無痛轉換也無法。
因此我們可以參考 Rust 標準函式庫為泛型參數 K 實作 Borrow trait,抽象化 owned 與 borrowed 間的型別,讓呼叫端無論傳 owned 或 borrowed 型別都可以有相同的行為。
#![allow(unused)] fn main() { pub fn get<Q>(&self, q: &Q) -> Option<&V> where K: Borrow<Q>, Q: Hash + Eq + ?Sized { let index = self.make_hash(q)?; self.buckets.get(index).and_then(|bucket| bucket.iter() .find(|(k, _)| q == k.borrow()) .map(|(_, v)| v) ) } }
fn get_mut()與fn get()的差異只在於呼叫了self.bucket.get_mut取得 mutable reference,這裡就不多做說明。
插入與刪除元素
插入與刪除比較特別,需要做些額外的功夫:
- 在操作完成之後需依據操作結果增減
HashMap.len,確保len永遠記錄正確的鍵值對數目。 - 在執行插入之前,需額外「動態調整」儲存空間,確保記憶體配置足夠空間新增元素。
先來看看刪除怎麼實作。
#![allow(unused)] fn main() { pub fn remove<Q>(&mut self, q: &Q) -> Option<V> where K: Borrow<Q>, Q: Hash + Eq + ?Sized { let index = self.make_hash(q)?; // 1 self.buckets.get_mut(index).and_then(|bucket| { // 2 bucket.iter_mut() .position(|(k, _)| q == (*k).borrow()) .map(|index| bucket.swap_remove(index).1) }).map(|v| { // 3 self.len -= 1; // Length decreases by one. v }) } }
- 所有涉及搜尋的操作,第一步一定是計算雜湊值。
- 建立 mutable 的疊代器,利用
posiion找到對應的鍵值對,再呼叫Vec::swap_remove移除。 - 前一步驟若有 return value 產生,表示移除一個元素,因此
self.len需手動減一。
Vec::swap_remove不需要 resize array,而是取得最後一個元素填補該空間,由於雜湊表的排序不重要,我們選擇swap_remove減少一點開銷。
而插入與移除非常相似。
#![allow(unused)] fn main() { pub fn insert(&mut self, key: K, value: V) -> Option<V> { self.try_resize(); // 1 let index = self // 2 .make_hash(&key) .expect("Failed to make a hash while insertion"); let bucket = self.buckets .get_mut(index) .expect(&format!("Failed to get bucket[{}] while insetion", index)); match bucket.iter_mut().find(|(k, _)| *k == key) { // 3 Some((_ , v)) => Some(mem::replace(v, value)), // 3.1 None => { bucket.push((key , value)); // 3.2 self.len += 1; None } } // 4 } }
- 嘗試調整雜湊表大小,以確保 load factor 在閾值之間。
- 同樣地,根據鍵計算雜湊值,以取得對應的內部 bucket 位置。
- 疊代整個 bucket 尋找鍵相同的鍵值對。
- 若找到,使用
mem::replace資料部分,不需取代整個鍵值對。 - 若找無,則新增一組新鍵值對到該 bucket 中,並將長度加一。
- 若找到,使用
- 若插入操作實際上是更新原有資料,則回傳被更新前的舊資料
Some((K, V)),反之則回傳None。
- 原則上「動態調整儲存空間」正確實作下,步驟二的
expect不會發生 panic。mem::replace可當作將同型別兩變數的記憶體位置互換,也就同時更新了原始資料。
動態調整儲存空間
動態調整儲存空間大概是整個實作中最詭譎的一部分。首先,我們需要知道
- 容器內鍵值對的總數:透過
self.len,我們將取得self.len的邏輯包裝在fn len(&self),以免未來長度移動至別處儲存計算。 - 容器內 bucket 的總數:計算
self.bucket.len(),同樣地,將之包裝在fn bucket_count(&self),並開放給外界呼叫。 - Load factor 閾值:記錄在
const LOAD_FACTOR,設定為 0.75。
前情提要完畢,接下來就是程式碼的部分了。
#![allow(unused)] fn main() { fn try_resize(&mut self) { let entry_count = self.len(); // 1 let capacity = self.bucket_count(); // Initialization. if capacity == 0 { // 2 self.buckets.push(Bucket::new()); return } if entry_count as f64 / capacity as f64 > LOAD_FACTOR { // 3 // Resize. Rehash. Reallocate! let mut new_map = Self::with_capacity(capacity << 1); // 4 self.buckets.iter_mut() // 5 .flat_map(|bucket| mem::replace(bucket, vec![])) .for_each(|(k, v)| { new_map.insert(k, v); }); *self = new_map; // 6 } } }
- 取得所有需要用到的長度資料。
- 若當前容量為 0,表示尚未新增任何元素,我們 push 一個空 bucket 進去,讓其他操作可以正常新增鍵值對。
- 判斷 load factor,決定需不需要動態調整大小。
- 透過
HashMap::with_capacity建立容量兩倍大的空雜湊表。 - 開始疊代舊的 bucket,並利用
flat_map打平 nested vector,再利用for_each將每個元素重新 insert 到新雜湊表。 - 把
self的值指向新雜湊表,舊雜湊表的記憶體空間會被釋放。
實作疊代器方法
一個集合型別當然少不了簡易的產生疊代器實作。
根據之前其他方法的實作,要疊代整個雜湊表非常簡單,就是疊代所有 bucket,並利用 flat_map 打平 nested vector。簡單實作如下:
#![allow(unused)] fn main() { fn iter() -> std::slice::Iter<(&k, &v)> { self.buckets.iter_mut() .flat_map(|b| b) .map(|(k, v)| (k, v)) } }
但最終會發現,我們的程式完全無法編譯,也無法理解這麼長的閉包(closure)究竟要如何寫泛型型別。得了吧 Rust,老子學不動了!
error[E0308]: mismatched types
--> src/collections/hash_map/mod.rs:253:9
|
253 | / self.buckets.iter()
254 | | .flat_map(|b| b)
255 | | .map(|(k, v)| (k, v))
| |_________________________________^ expected struct `std::slice::Iter`, found struct `std::iter::Map`
|
= note: expected type `std::slice::Iter<'_, (&K, &V)>`
found type `std::iter::Map<std::iter::FlatMap<std::slice::Iter<'_, std::vec::Vec<(K, V)>>, &std::vec::Vec<(K, V)>, [closure@src/collections/hash_map/mod.rs:254:23: 254:28]>, [closure@src/collections/hash_map/mod.rs:255:18: 255:33]>`
幸好,在 Rust 1.26 釋出時,大家期待已久的 impl trait 穩定了。如同字面上的意思,impl trait 可以用在函式參數與回傳型別的宣告中。代表這個型別有 impl 對應的 trait,所以不必再寫出落落長的 Iterator 泛型型別。impl trait 有另一個特點是以靜態分派(static dispatch)來呼叫函式,相較於 trait object 的動態分派(dynamic dispatch),impl trait 毫無效能損失。
實作如下:
#![allow(unused)] fn main() { pub fn iter(&self) -> impl Iterator<Item = (&K, &V)> { self.buckets.iter() .flat_map(|b| b) .map(|(k, v)| (k, v)) } }
更多 impl trait 相關資訊可以參考:
- Rust RFC: impl trait
- Rust 1.26: impl trait
- Rust Reference: Trait objects
- The Rust Programming Language: Trait objects
效能
以陣列實作的雜湊表各操作複雜度如下
| Operation | Best case | Worst case |
|---|---|---|
| add(k, v) | $O(1)$~ | $O(n)$ |
| update(k, v) | $O(1)$ | $O(n)$ |
| remove(k) | $O(1)$~ | $O(n)$ |
| search(k) | $O(1)$ | $O(n)$ |
$n$:資料筆數。
$k$:欲綁定資料的鍵。
$v$:欲與鍵綁定的資料。
~:平攤後的複雜度(amortized)。
時間複雜度
在預期情況下,只要雜湊函數品質穩定,大部分操作都可達到在常數時間, 但由於部分操作,尤其是新增或刪除元素的操作,會需要調整 bucket array 的空間,重新配置記憶體空間,所以需要平攤計算複雜度。
而最差複雜度出現在每個元素都發生雜湊碰撞。若使用 open addressing 處理碰撞,則會把雜湊表配置的每個位置都填滿,而所有操作都從同個位置開始,搜尋對應的鍵,複雜度與陣列的線性搜索相同為 $O(n)$;若使用 separate chaining,碰撞代表所有元素都會在同一個 bucket 裡面,也就是只有一個 bucket 上會有一個長度為 n ,被塞滿的陣列或鏈結串列,結果同樣是線性搜索的 $O(n)$。
我們嘗試使用數學表示搜索的複雜度。另
- $n$:已放入雜湊表內的資料總數。
- $k$:雜湊表配置的儲存空間(bucket 總數)。
- $\text{load factor} = \frac{n}{k}$:預期每個 bucket 儲存的資料筆數。
則預期執行時間為
$$\Theta(1+\frac{n}{k}) = O(1) \ \text{ if } \frac{n}{k} = O(1)$$
而 1 為計算雜湊與取得索引(random access)的執行時間,$\frac{n}{k}$ 則是搜尋陣列的執行時間。只要 load factor 越接近 $n$,執行時間就相對增加。
空間複雜度
雜湊表的空間複雜度取決於實作預先配置的陣列大小,並與維持 load factor 息息相關。一般來說,仍與資料筆數成線性關係,因此空間複雜度只有資料本身 $O(n)$。而以 separate chaining 會額外配置陣列或鏈結串列儲存碰撞元素,理論上需負擔更多額外的指標儲存空間。
參考資料
- Rust Documentation: HashMap
- Wiki: Hash table
- Wiki: Open addressing
- Algorithms, 4th Edition by R. Sedgewick and K. Wayne: 3.4 Hash Tables
- MIT 6.006: Introduction to Algorithms, fall 2011: Unit 3 Hashing
- Map graph by Jorge Stolfi CC BY-SA-3.0 via Wikimedia Commons.